
We have a guest contribution from Zvi Or-Bach, the President and CEO of MonolithIC 3D Inc. Mr. Or-Bach discusses about the emergence of monolithic 3D technology in the near future.
The coming 2014 IEEE S3S conference (October 6-9) is first one to focus on the emergence of monolithic 3D technology. It is fitting that it would be the forum at which a key decisive breakthrough for monolithic 3D IC ("M3DI") technology will be presented. This game changing breakthrough is the first ever monolithic 3D flow that allows a fab to build a monolithic 3D integrated device while using the fab’s existing transistor process flow, without the need to develop and qualify new transistors and a new transistor formation flow.
Recent blogs such as Established Nodes Getting New Attention and Moore's Lag Shifts Paradigm of Semi Industry have articulated the building up of interest in SOI, Sub-threshold and 3D IC technologies. The IEEE S3S is the conference to learn and get updated on these technologies and M3DI is that newest part integrated into the conference. The 3D part of S3S 2014 will have a full day of tutorial presentations by leading researchers in the space, a full session of invited papers, and will conclude with a session dedicated to discussing the most recent breakthroughs in the field.
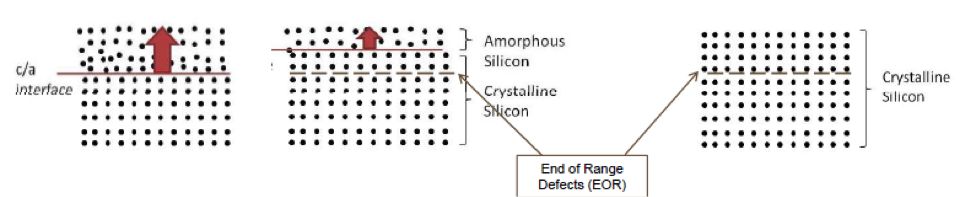
The M3DI short course will cover alternative process flows that enable M3DI, discuss the challenges and solutions to removal of the operating heat of monolithic 3D stacks, and describe the range of powerful advantages provided by M3DI. Subsequently, Prof. Sung Kyu Lim of Georgia Tech will cover EDA for M3DI. This will be followed by broad coverage of M3DI for memory applications by two leading experts in the field, Akihiro Nitayama of Toshiba/Tokohu University and Deepak Sekar of Rambus. M3DI provides unparalleled heterogeneous integration options which will be covered by Prof. Eugene Fitzgerald of MIT and SMART Lee Institute of Singapore describing the integration of silicon with other crystals for electro-optic device integration. The short course will conclude with Prof. Philip Wong of Stanford, who leads research efforts to integrate silicon with carbon nanotube and advanced 2D transistors layered with memory such as STT-MRAM and RRAM.
Recent blogs such as Established Nodes Getting New Attention and Moore's Lag Shifts Paradigm of Semi Industry have articulated the building up of interest in SOI, Sub-threshold and 3D IC technologies. The IEEE S3S is the conference to learn and get updated on these technologies and M3DI is that newest part integrated into the conference. The 3D part of S3S 2014 will have a full day of tutorial presentations by leading researchers in the space, a full session of invited papers, and will conclude with a session dedicated to discussing the most recent breakthroughs in the field.
The M3DI short course will cover alternative process flows that enable M3DI, discuss the challenges and solutions to removal of the operating heat of monolithic 3D stacks, and describe the range of powerful advantages provided by M3DI. Subsequently, Prof. Sung Kyu Lim of Georgia Tech will cover EDA for M3DI. This will be followed by broad coverage of M3DI for memory applications by two leading experts in the field, Akihiro Nitayama of Toshiba/Tokohu University and Deepak Sekar of Rambus. M3DI provides unparalleled heterogeneous integration options which will be covered by Prof. Eugene Fitzgerald of MIT and SMART Lee Institute of Singapore describing the integration of silicon with other crystals for electro-optic device integration. The short course will conclude with Prof. Philip Wong of Stanford, who leads research efforts to integrate silicon with carbon nanotube and advanced 2D transistors layered with memory such as STT-MRAM and RRAM.
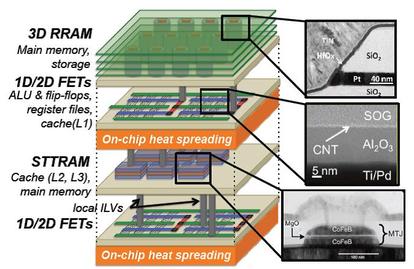
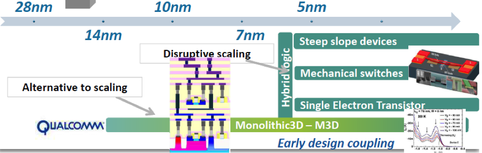
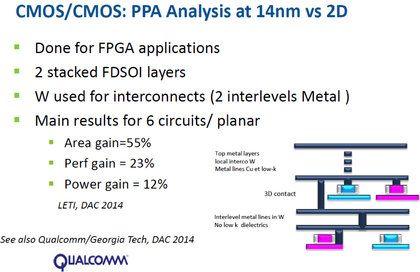
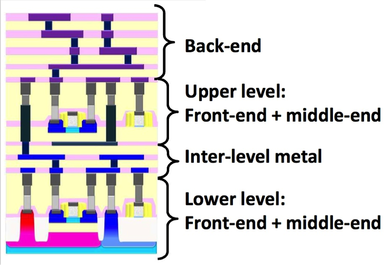
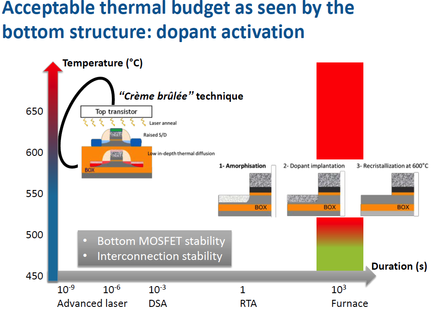
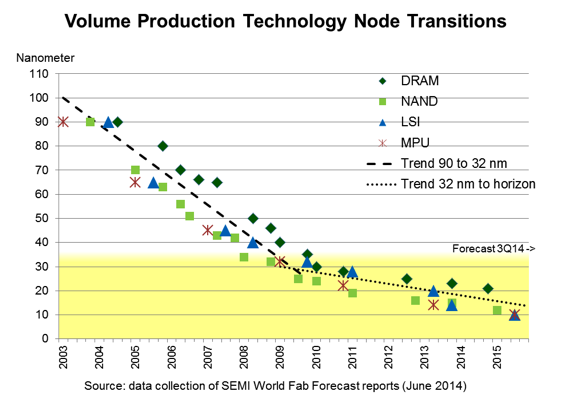
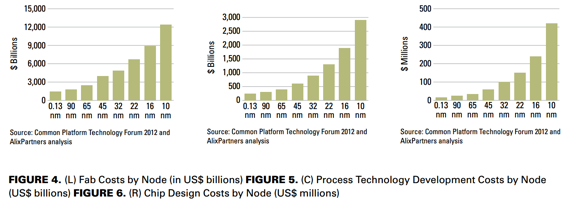
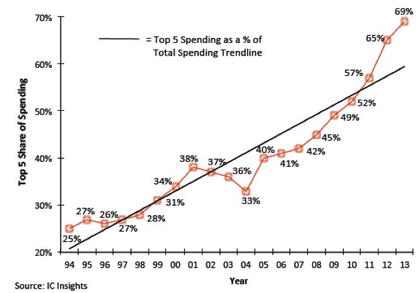
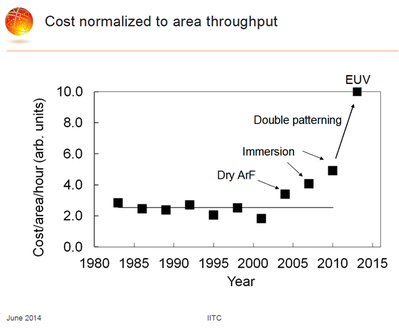
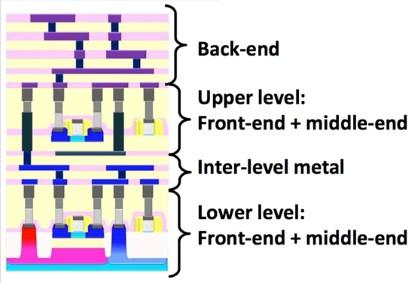
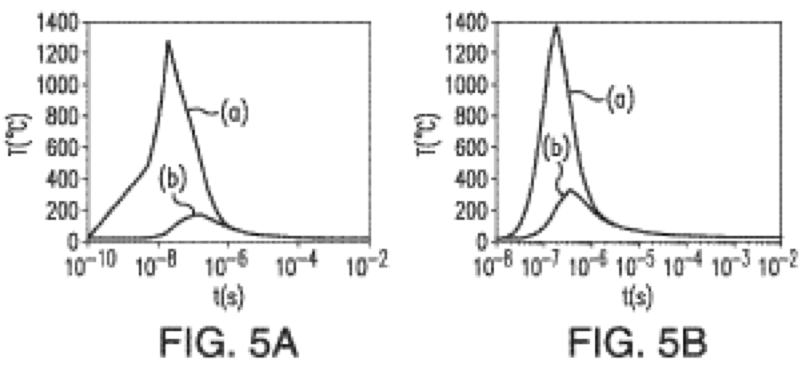
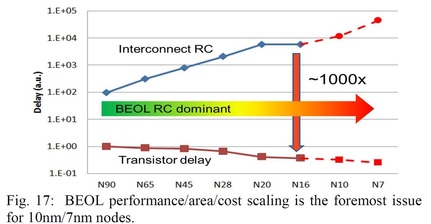
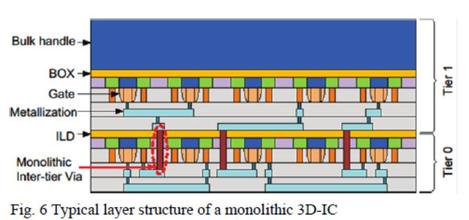
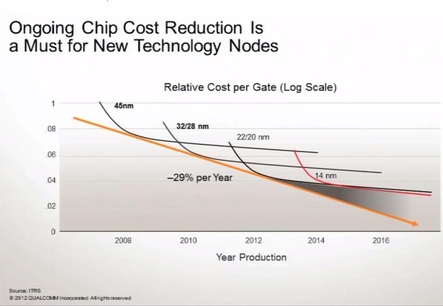
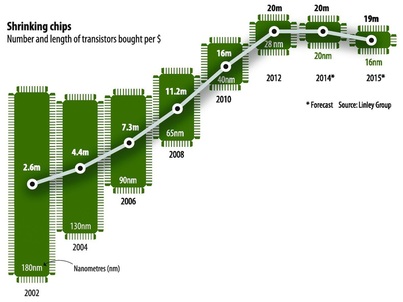
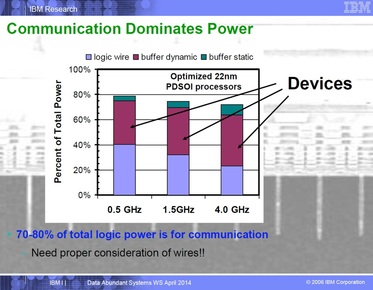
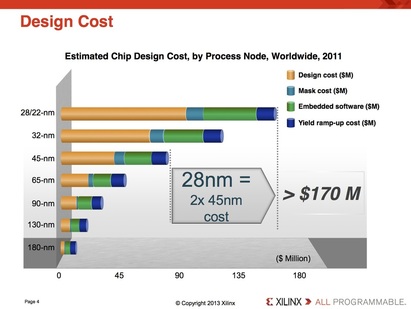
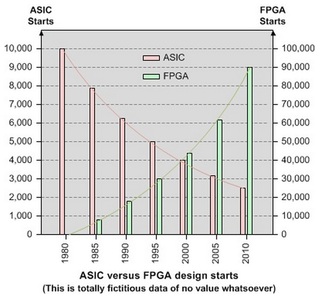
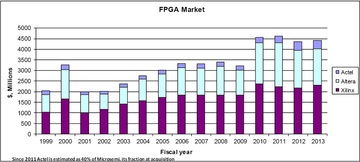
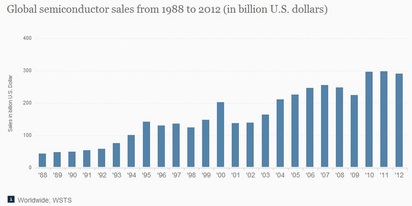
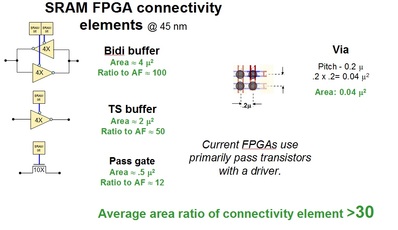
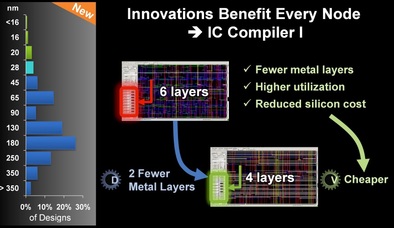
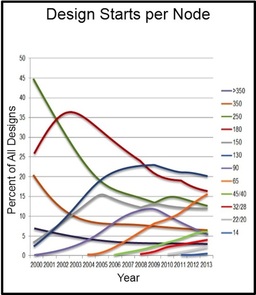
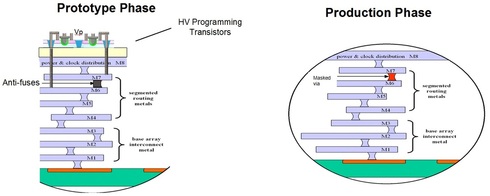
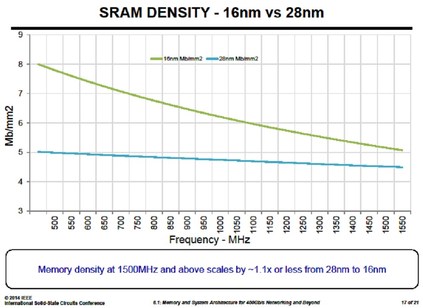
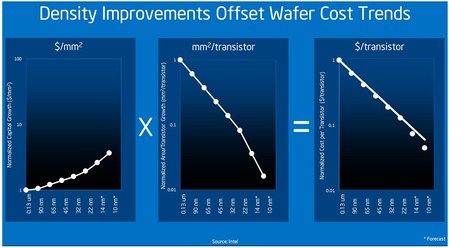
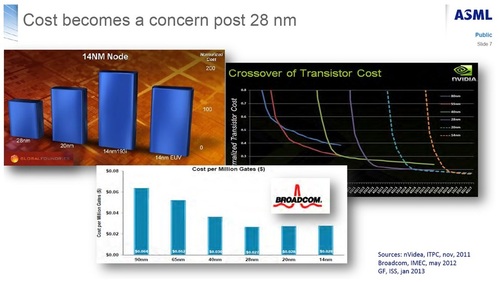
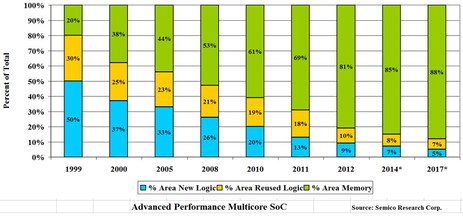
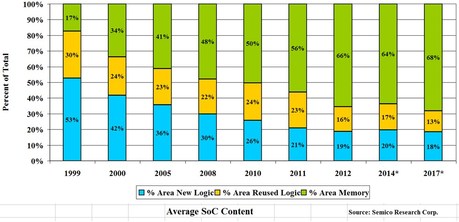
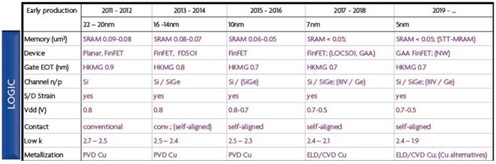
In the special invited 3D Hot Topics session we expect to get a full spectrum of the latest progress in the field. Particularly worth noting is the recent progress on the work done by CEA Leti with involvement of ST Micro, IBM and supported by Qualcomm. This work shows both a practical path to monolithic 3D IC and cost analysis of the monolithic 3D advantages. The following chart illustrates the reasons for the high interest in the technology.
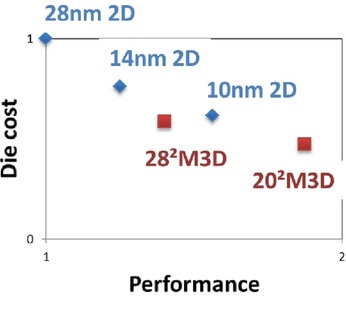
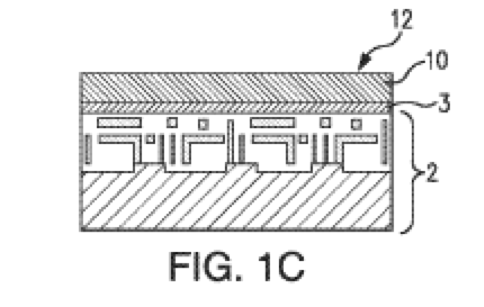
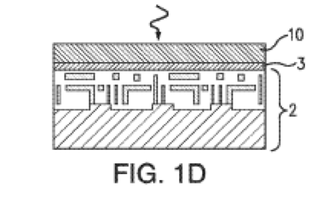
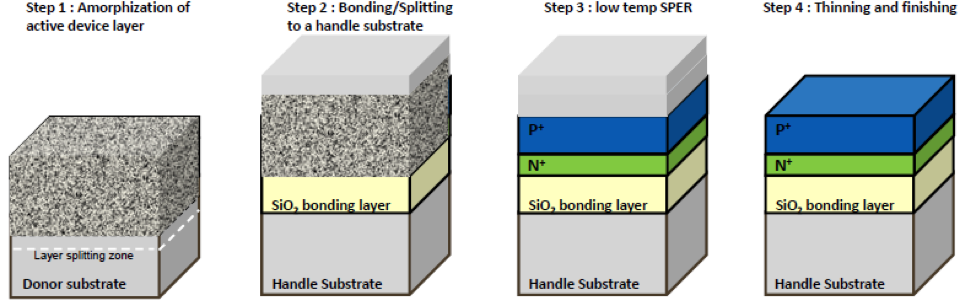
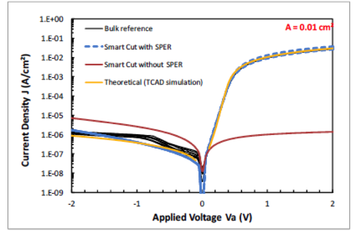
And then there is a great dessert to this 3D feast. On Thursday afternoon, in the 3D New Developments session, a game changing breakthrough technology will be presented. Leveraging the breakthrough progress in wafer bonding technology, presenting for the first time ever a monolithic 3D flow using existing fab transistor process. Any fab could utilize this breakthrough to provide far better products at minimum capital and R&D investment. This game changing flow removes the historical differentiation between sequential and parallel 3D, and should significantly reduce the time for monolithic 3D adoption throughout the semiconductor industry.
For a postprandial enjoyment, CEA Leti will present in the Late News session a fully constructed M3DI SOI device, and IBM will present its Multi Stacked Memory Wafer technology.
More information is available on the conference site: S3S Conference 2014
For a postprandial enjoyment, CEA Leti will present in the Late News session a fully constructed M3DI SOI device, and IBM will present its Multi Stacked Memory Wafer technology.
More information is available on the conference site: S3S Conference 2014


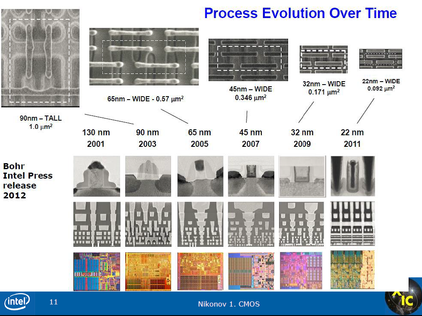
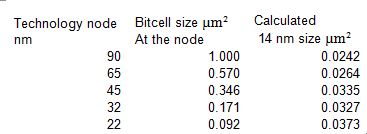



















 RSS Feed
RSS Feed