
We have a guest contribution from Zvi Or-Bach, the President and CEO of MonolithIC 3D Inc. Mr. Or-Bach discusses about the FPGA as ASIC Alternative.
In our recent blog 28nm – The Last Node of Moore's Law we outlined the recent dramatic change that has happened after many years of cost reduction associated with dimensional scaling. It is clear now that 28 nm will provide the lowest cost per gate for years to come. In this blog we will assess the potential implications for the ASIC and the FPGA markets. Over the last two decades we have seen escalating mask set costs associated with dimensional scaling and accordingly escalating NRE costs. At the recent 2014 SEMI Industry Strategy Symposium (ISS) Ivo Bolsens, Xilinx CTO, presented the following chart of ASIC design cost escalation:
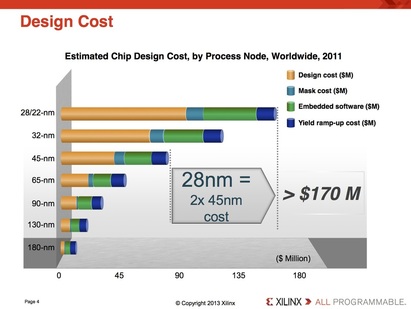
Figure 1
The dramatic increases of ASIC design cost have had a real effect on the ASIC market, reducing the number of new designs and dramatically reducing the number of vendors serving the ASIC market.
One would expect that such a trend would have a very positive effect on the FPGA market, as there is no mask-set cost associated with an FPGA design and, accordingly, far lower NRE costs per design. The following fictitious chart presented in the EE Times article: What’s the number of ASIC versus FPGA design starts?, illustrates these expectations.
One would expect that such a trend would have a very positive effect on the FPGA market, as there is no mask-set cost associated with an FPGA design and, accordingly, far lower NRE costs per design. The following fictitious chart presented in the EE Times article: What’s the number of ASIC versus FPGA design starts?, illustrates these expectations.
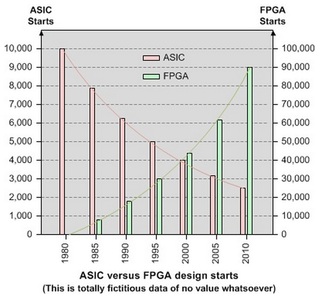
Figure 2
Surprisingly, this did not really happen. The following chart presents the overall FPGA market during the last decade according to the financial results of Xilinx, Altera and Actel.
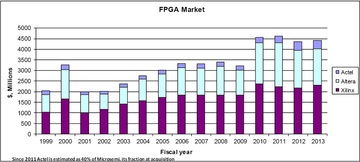
Figure 3
The FPGA market growth could be compared to the overall semiconductor market growth as presented in the chart below (the market in 2013 was $305B). Clearly the FPGA market growth during the last decade is similar to the overall semiconductor market growth, and there is no indication of any benefits from the escalating ASIC mask-set cost and its associated NRE.
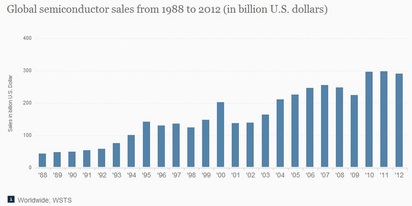
Figure 4
The FPGA technology started in the mid-1980s as an alternative to the popular ASIC technology then – the Gate Array. The acronym FPGA stands for Field Programmable Gate Array. During the 1990s the Gate Array technology lost its appeal and the ~$20B Gate Array market shrunk dramatically and effectively ceased to exist. Analyst expected that this will have a dramatic positive impact on the FPGA market, which did grow some but far from the expectations. The trend of escalating NRE driven by dimensional scaling and escalating lithography costs kept on going in the 2000s and drove down the number of ASIC designs. And, again, analysts expected a huge surge in the FPGA market. Clearly, this did not happen.
In the following we will present our theory why it did not happen and some potential implications for the future.
We believe that the stagnation of FPGA growth is mostly due to the inefficiency of the FPGA technology. Most FPGAs use SRAM as the programming or ‘switch’ technology. Interconnects are the dominating resource in modern designs. Within an SRAM based FPGA the programming of interconnects is implemented by an SRAM cell control of a pass transistor, driver, or bidirectional driver. The following chart illustrates the diffusion area associated for such Programmable Interconnect Cell (PIC) assessed in 45nm technology and compared to the size of mask-defined equivalent – the via. The results indicate that the cell area overhead for the SRAM PIC is over 30X when compared to a via, which does not include the additional circuit overhead area needed to program and control the SRAM PIC.
In the following we will present our theory why it did not happen and some potential implications for the future.
We believe that the stagnation of FPGA growth is mostly due to the inefficiency of the FPGA technology. Most FPGAs use SRAM as the programming or ‘switch’ technology. Interconnects are the dominating resource in modern designs. Within an SRAM based FPGA the programming of interconnects is implemented by an SRAM cell control of a pass transistor, driver, or bidirectional driver. The following chart illustrates the diffusion area associated for such Programmable Interconnect Cell (PIC) assessed in 45nm technology and compared to the size of mask-defined equivalent – the via. The results indicate that the cell area overhead for the SRAM PIC is over 30X when compared to a via, which does not include the additional circuit overhead area needed to program and control the SRAM PIC.
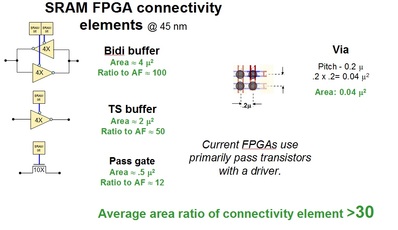
Figure 5
This number had been reported in the industry for many years. A 2007 research paper by Ian Kuon and Prof Jonathan Rose (IEEE Transaction on Computer-Aided Design of IC and System) says this clearly: “In this paper, we have presented empirical measurements quantifying the gap between FPGAs and ASICs for core logic. We found that for circuits implemented purely using the LUT based logic elements, an FPGA is approximately 35 times larger and between 3.4 to 4.6 times slower on average than a standard-cell implementation.”
This high programmability overhead suggests that many of the current ASIC designs cannot be replaced by an FPGA design. Consequently, when advanced technology NRE is too high, the alternative is to use older node ASIC technologies. Since the number one driver for cost of mask-sets and NRE is the associated capital, the cost of older technologies goes down dramatically over time. The 30X area penalty means that one could use a node that is five generations older and have a competitive solution when compared to current node FPGA. Taking into account the 60% gross margin of the FPGA companies and the overhead of using a fixed-sized device of an FPGA family rather than a custom tailored Standard Cell device, these could compensate for an additional two nodes. Looking again at the design costs as illustrated in the Xilinx chart above, we can see that at 180 nm the design costs are pretty low and the mask set costs are too small even to register on the chart.
This high programmability overhead suggests that many of the current ASIC designs cannot be replaced by an FPGA design. Consequently, when advanced technology NRE is too high, the alternative is to use older node ASIC technologies. Since the number one driver for cost of mask-sets and NRE is the associated capital, the cost of older technologies goes down dramatically over time. The 30X area penalty means that one could use a node that is five generations older and have a competitive solution when compared to current node FPGA. Taking into account the 60% gross margin of the FPGA companies and the overhead of using a fixed-sized device of an FPGA family rather than a custom tailored Standard Cell device, these could compensate for an additional two nodes. Looking again at the design costs as illustrated in the Xilinx chart above, we can see that at 180 nm the design costs are pretty low and the mask set costs are too small even to register on the chart.
What has really happened is that many designs chose to use older node standard cells instead of an FPGA. In his last keynote presentation at the Synopsys user group (SNUG 2014) Art De Geus, Synopsys CEO, presented multiple slides to illustrate the value of Synopsys newer tools to improve older node design effectiveness. The following chart is one of them and it also includes in its left side the current distribution of design starts. One can easily see that the most popular current design node is at 180nm. Clearly even such old node provides a better product than the state of the art FPGA.
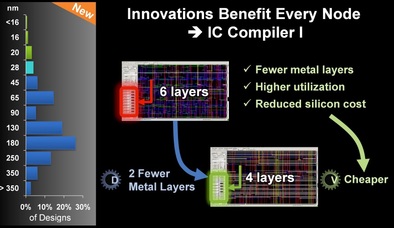
Figure 6
Now we understand why the escalating mask set and NRE costs have not resulted in a surge of FPGA designs but rather pushed designers to user older technology nodes that had depreciated enough to make their NRE cost less of an issue. The following chart of Design Starts per Node by IBS was recently presented in a Synopsys article "The new landscape of advanced design". It shows the design starts trend over time and, not surprisingly, indicates that designers migrate to more advanced nodes over a longer time and that the up and coming node these days is just 65 nm.
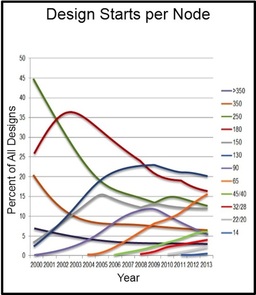
Figure 7 - Design Starts per Year (Source: IBS Dec 2012)
Recently EE Times published our blog, 28nm – The Last Node of Moore's Law. In it we presented that the 28nm node will be the end of cost reduction for dimensional scaling. Most analysts accept by now that 28 nm is going to be the lowest cost per gate for many years to come.
There are potentially many implications of this change in Moore’s Law. One of those implications could affect the future of FPGAs.
Traditionally FPGAs have been, and still are, a technology driver of new logic technology nodes. This early adoption gave the FPGA customer a constantly better programmable platform for their designs. Now that dimensional scaling does not provide better cost, it will result in a build-up of pressure for FPGA customers to use a depreciated technology node as an alternative. Over time designers would see the NRE of 65nm going down to about what the 180nm NRE is today. Comparing a 65nm Standard Cell design to an FPGA of 28nm suggests that far more designs could be better off with Standard Cell. As 20 nm and 14 nm FPGAs would not provide a better cost than the 28 nm one, it means that the FPGA market could see a growing challenge in the coming years.
Designers chose older nodes not just for its lower mask-set and NRE costs but also for availability of broader embedded options such as flash memories and analog cells. But those are becoming available on newer nodes over time as well. The 65 nm node is now ramping up and would become the preferred choice for new designs in a few years, as its mask-set cost and NRE keep going down thanks to deprecation and broader availability. As volume production of older designs winds down, vendors are reducing their costs to bring new designs in, and will soon make the 65 nm as easy to access as 180 nm is now. FPGA vendors will release newer products on 20nm and 14nm but those would not offer lower production costs than the 28 nm FPGA products and will be less and less competitive versus a ‘not too old’ technology node such as 65 nm. It only seems logical that these new semiconductor industry dynamics will have a negative effect on the FPGA market and a positive effect on ASIC and Structured ASIC technologies.
Thus it behooves us to consider what can the FPGA vendors do to keep their business growth.
Interestingly, the same trend that now works against FPGA technologies could be used to improve their competitiveness. In the early days two major FPGA technologies were competing in the market. The SRAM technology and the anti-fuse technology. The SRAM technology had higher switch overhead, but ended up winning because it benefitted from two major advantages. First, it did not need any major process changes and could be adapted to newer nodes as soon as those could be fabricated. Second was their ability to reprogram the device over and over again. Now that new process nodes do not provide lower costs, FPGA vendors could look to other than SRAM technology as a new path to improve their programmable platforms. As for anti-fuse, the significant effort in recent years to develop RRAM technology opens the possibility of adopting antifuse technology that could offer re-programmability. Even more important is the fact that re-programmability these days is far less important as all FPGA designs utilize simulation technology and other EDA tools, as the trial and error methodology no longer can be effectively used for modern designs.
A special type of antifuse programmable technology could be most effective – Antifuse-based 3D High Density FPGA. This type of programmable fabric leverages anti-fuse metal to metal technology, which use 3D transistors for programming the anti-fuses. The 3D transistors could handle the higher voltage required for the programming and provide the interconnect programming with minimal device density impact. The 3D anti-fuse programmable fabric density is very similar to a via programmable fabric. Via programmable fabrics has been used with structured ASICs such as those offered by eASIC and Triad Semiconductors (ViASIC). They provide a programmable fabric with about a 2X area penalty vs. mask-defined standard cell technologies. These antifuses could be made as one time or reprogrammable devices and be fully replaced by mask-defined vias for even lower cost volume production, as illustrated by the following chart
There are potentially many implications of this change in Moore’s Law. One of those implications could affect the future of FPGAs.
Traditionally FPGAs have been, and still are, a technology driver of new logic technology nodes. This early adoption gave the FPGA customer a constantly better programmable platform for their designs. Now that dimensional scaling does not provide better cost, it will result in a build-up of pressure for FPGA customers to use a depreciated technology node as an alternative. Over time designers would see the NRE of 65nm going down to about what the 180nm NRE is today. Comparing a 65nm Standard Cell design to an FPGA of 28nm suggests that far more designs could be better off with Standard Cell. As 20 nm and 14 nm FPGAs would not provide a better cost than the 28 nm one, it means that the FPGA market could see a growing challenge in the coming years.
Designers chose older nodes not just for its lower mask-set and NRE costs but also for availability of broader embedded options such as flash memories and analog cells. But those are becoming available on newer nodes over time as well. The 65 nm node is now ramping up and would become the preferred choice for new designs in a few years, as its mask-set cost and NRE keep going down thanks to deprecation and broader availability. As volume production of older designs winds down, vendors are reducing their costs to bring new designs in, and will soon make the 65 nm as easy to access as 180 nm is now. FPGA vendors will release newer products on 20nm and 14nm but those would not offer lower production costs than the 28 nm FPGA products and will be less and less competitive versus a ‘not too old’ technology node such as 65 nm. It only seems logical that these new semiconductor industry dynamics will have a negative effect on the FPGA market and a positive effect on ASIC and Structured ASIC technologies.
Thus it behooves us to consider what can the FPGA vendors do to keep their business growth.
Interestingly, the same trend that now works against FPGA technologies could be used to improve their competitiveness. In the early days two major FPGA technologies were competing in the market. The SRAM technology and the anti-fuse technology. The SRAM technology had higher switch overhead, but ended up winning because it benefitted from two major advantages. First, it did not need any major process changes and could be adapted to newer nodes as soon as those could be fabricated. Second was their ability to reprogram the device over and over again. Now that new process nodes do not provide lower costs, FPGA vendors could look to other than SRAM technology as a new path to improve their programmable platforms. As for anti-fuse, the significant effort in recent years to develop RRAM technology opens the possibility of adopting antifuse technology that could offer re-programmability. Even more important is the fact that re-programmability these days is far less important as all FPGA designs utilize simulation technology and other EDA tools, as the trial and error methodology no longer can be effectively used for modern designs.
A special type of antifuse programmable technology could be most effective – Antifuse-based 3D High Density FPGA. This type of programmable fabric leverages anti-fuse metal to metal technology, which use 3D transistors for programming the anti-fuses. The 3D transistors could handle the higher voltage required for the programming and provide the interconnect programming with minimal device density impact. The 3D anti-fuse programmable fabric density is very similar to a via programmable fabric. Via programmable fabrics has been used with structured ASICs such as those offered by eASIC and Triad Semiconductors (ViASIC). They provide a programmable fabric with about a 2X area penalty vs. mask-defined standard cell technologies. These antifuses could be made as one time or reprogrammable devices and be fully replaced by mask-defined vias for even lower cost volume production, as illustrated by the following chart
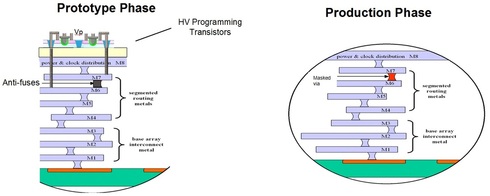
Figure 8
Going forward, the semiconductor industry needs to go through fundamental change. No longer is it sufficient to scale using the next node of dimensional scaling to provide better overall device value. From the 28 nm node going forward, the industry needs to open up for a broad range of innovation so to continue offering better products. We can only hope that this will drive the industry back to fast growth and support the future market of Internet-of-Things and Internet-of-Everything.








 RSS Feed
RSS Feed