28nm: Clearly the Last Node of Moore's Law for Most Designs

We have a guest contribution from Zvi Or-Bach, the President and CEO of MonolithIC 3D Inc. Mr. Or-Bach discusses about the paradigm shift in the semiconductor industry.
In our blog 28nm – The Last Node of Moore's Law, we had pointed out that the change has happened, and it is no longer a matter of forecast or prediction. In this blog we will start by reviewing some of what has transpired since that blog, and then focus on the ensuing paradigm shift in the semiconductor industry.
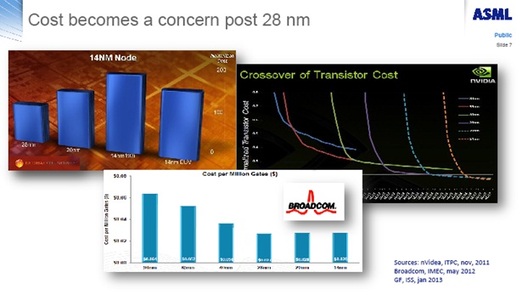
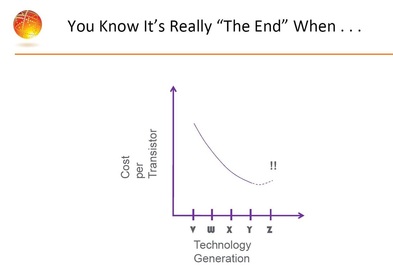
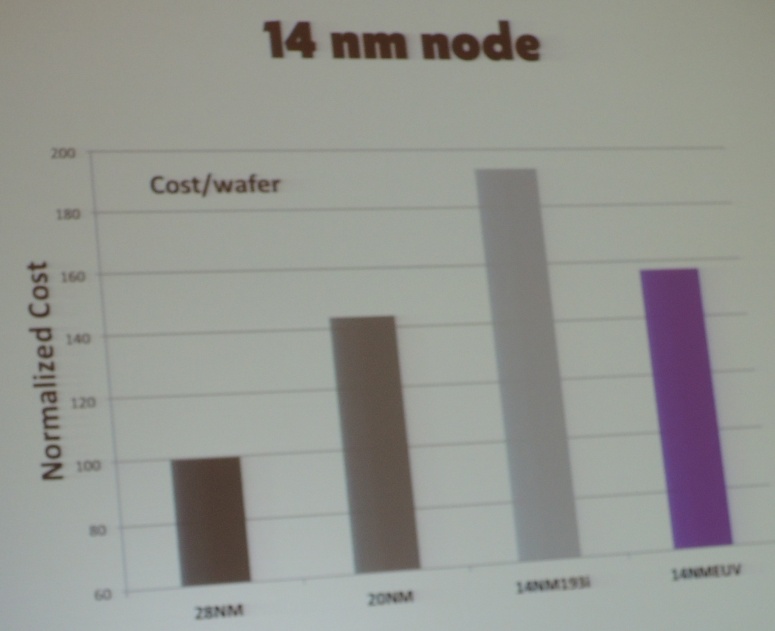
The following chart was presented in the IEEE IITC workshop by Globalfoundries. It illustrates the cost impact of the double patterning required for scaling below 28/22 nm.
The following chart was presented in the IEEE IITC workshop by Globalfoundries. It illustrates the cost impact of the double patterning required for scaling below 28/22 nm.
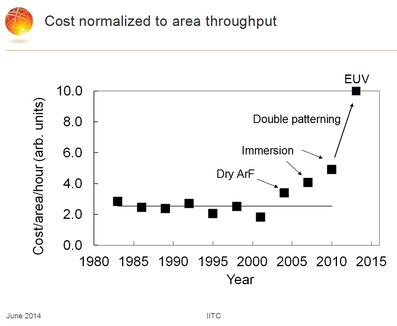
Soon after Rick Merritt’s coverage of Semicon West - 13 Things I Heard at Semicon West -- Rick wrote: "Moore's Law has definitely slowed" quoting Gartner semiconductor analyst Bob Johnson."No matter what Intel says, Moore's Law is slowing down" and, Bob added, "Only a few high-volume, high-performance apps can justify 20 nm and beyond."
Soon thereafter Peter Singer, in a blog post about the ConFab 2014 – Can we take cost out of technology scaling? -- quotes Dr. Gary Patton, VP of semiconductor research and development center at IBM: “The challenge we’re facing now is two fold. Number one, we’re struggling to get that 0.7X linear scaling. It might be about 0.8X. And we’re adding a lot more complexity, especially when you adding double and triple patterning."
And now, in early August we finaly got more information from Intel about their up coming 14nm. In our blog Intel vs. Intel we articulate that Intel’s numbers indicate that Moore’s Law had stopped at 28/22 nm both in terms of the bring-up time it takes and the cost of new technology nodes.
It is hard to accept that a trend that has held strong for 50 years, and which kept going many years after multiple predictions of its imminent demise, has really stopped. And it is even harder as we watch the huge effort of bringing up the 14 nm and 10 nm nodes. Yet it seems that everybody should agree that the semiconductor industry is now going through a paradigm shift and for most designs 28nm is, at least for some time, the last node of Moore's Law.
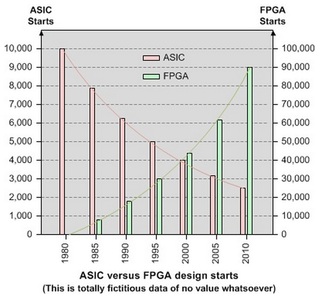
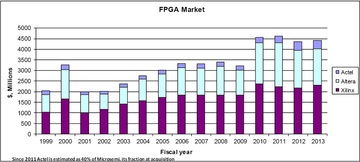
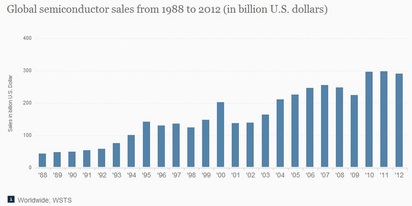
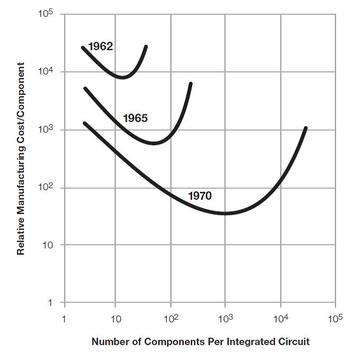
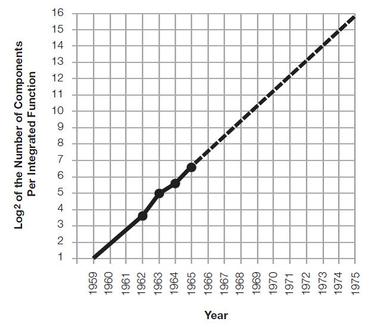
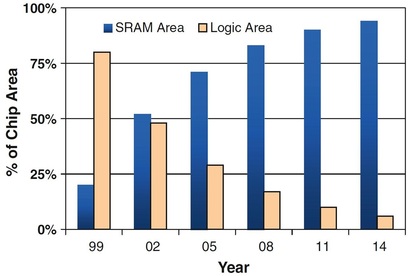
The following charts are well known and present the reason for that change.
Soon thereafter Peter Singer, in a blog post about the ConFab 2014 – Can we take cost out of technology scaling? -- quotes Dr. Gary Patton, VP of semiconductor research and development center at IBM: “The challenge we’re facing now is two fold. Number one, we’re struggling to get that 0.7X linear scaling. It might be about 0.8X. And we’re adding a lot more complexity, especially when you adding double and triple patterning."
And now, in early August we finaly got more information from Intel about their up coming 14nm. In our blog Intel vs. Intel we articulate that Intel’s numbers indicate that Moore’s Law had stopped at 28/22 nm both in terms of the bring-up time it takes and the cost of new technology nodes.
It is hard to accept that a trend that has held strong for 50 years, and which kept going many years after multiple predictions of its imminent demise, has really stopped. And it is even harder as we watch the huge effort of bringing up the 14 nm and 10 nm nodes. Yet it seems that everybody should agree that the semiconductor industry is now going through a paradigm shift and for most designs 28nm is, at least for some time, the last node of Moore's Law.
The following charts are well known and present the reason for that change.
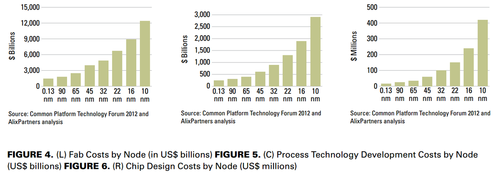
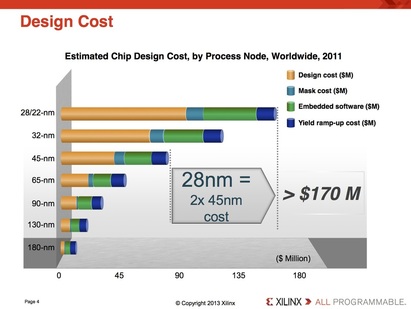
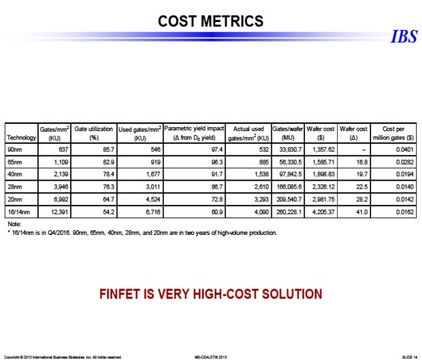
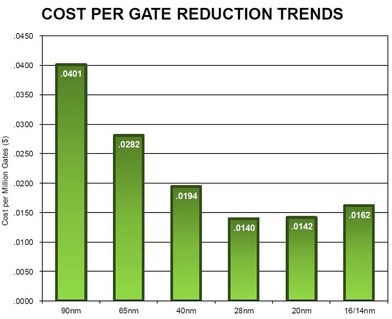
It shows that the design cost increases by more than $100M from 32nm to 16nm. If we assume a die cost of $10 at 32 nm and we assume that the traditional cost reduction per node still holds, then we would need a volume of more than 20 million units just to break even. If one also considers the risk associated which such a design, it would actually require more than 100 million units, or at least $1B of market, for such device to justify the investment. Clearly, very few designs have the market for 100 million units or $1B market.
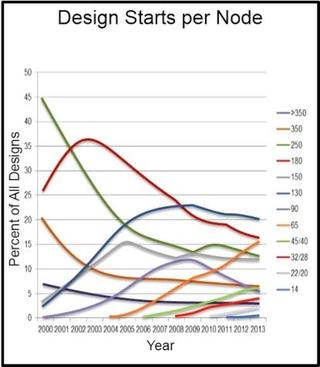
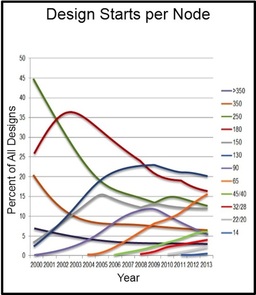
The following chart by IBS presents the past trend in design starts per node. Clearly, most new designs are still done in 130 nm while the node with the fastest ramp-up is 65 nm.
The following chart by IBS presents the past trend in design starts per node. Clearly, most new designs are still done in 130 nm while the node with the fastest ramp-up is 65 nm.
The forcast for 2016 at Semiconductor Technology Nodes – History, Trends and Forecast is illustrated in the following pie chart:
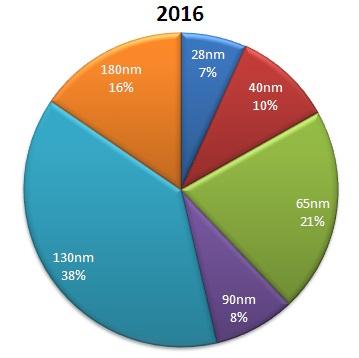
Yet again it indicates a very slow shift to more advanced nodes, and the expectationis that even in 2016 most new designs will still be done in 130nm.
This is clearly a paradigm shift in the industry, and the industry is responding accordingly.
Just prior to 2014 Semicon West, we have seen the conclusions of the SEMI’s World Fab Forecast -- Technology Node Transitions Slowing Below 32 nm. The Forecast uses a bottom-up methodology, providing high-level summaries and graphs, and in-depth analyses of capital expenditures, capacities, technology and products by fab. The chart below illustrates this new paradigm.
This is clearly a paradigm shift in the industry, and the industry is responding accordingly.
Just prior to 2014 Semicon West, we have seen the conclusions of the SEMI’s World Fab Forecast -- Technology Node Transitions Slowing Below 32 nm. The Forecast uses a bottom-up methodology, providing high-level summaries and graphs, and in-depth analyses of capital expenditures, capacities, technology and products by fab. The chart below illustrates this new paradigm.
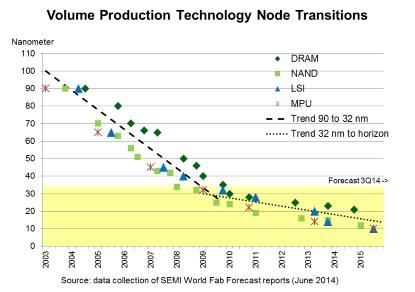
The report states: “The cost per wafer has become an increasing concern below the 32nm node. The expected cost reduction benefit of production at smaller nodes is diminishing and is not keeping pace with the scaling benefits in many cases. This has widespread and fundamental implications for an industry long following the cadences of Moore’s Law… These may be contributing factors as to why some volume fabs are exhibiting a lag in beginning production of a new technology node. Now evident quantitatively for the first time, there is evidence of a clear slowdown in volume production scaling of leading technology node transitions.” (emphasis added)
This was followed by another EE Times article – Silicon Highway Narrows, Twists: “Most foundries have yet to start buying the capital equipment needed for the 14/16 nm node, which for many will be the first to support FinFETs, says Trafas of KLA-Tencor. Gear companies hope the orders start coming in the fall…Indeed, he says, one of the big questions many capital equipment execs will bring to this year's Semicon West event on July 7 is, "When will the 16/14 nm investments begin?"
In the same vein, Ed Sperling continued in Established Nodes Getting New Attention: "Work is under way to improve energy efficiency and boost performance without relying on multi-patterning or finFETs. As the price of shrinking features increases below 28nm, there has been a corresponding push to create new designs at established nodes using everything from near-threshold computing to back biasing and mostly accurate analog sensors."
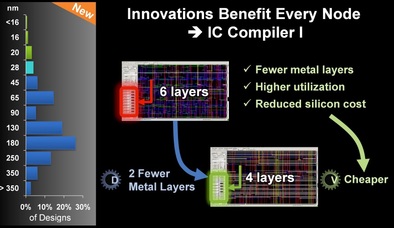
And a week later Samuel Wang, an analyst with Gartner, in Who’s Winning The FinFET Foundry Race? wrote: “Short-term, during the first two years of finFET production, there is no need for more than 50,000 wafers a month capacity from all foundries to satisfy the market demand for finFETs, …In the long run and before 2018, there is no need to have more than 250K wafers a month capacity to support the market demand for finFETs." The EDA industry also is recognizing this paradigm shift. Dr. Aart de Geus in his keynote to the 2014 Synopsys User Group titled Designing Change Into Semiconductor Techonomics, recognized this shift with a series of slides articulating how EDA tools that were developed to support the new technology nodes could also benefit design efforts of old nodes:
This was followed by another EE Times article – Silicon Highway Narrows, Twists: “Most foundries have yet to start buying the capital equipment needed for the 14/16 nm node, which for many will be the first to support FinFETs, says Trafas of KLA-Tencor. Gear companies hope the orders start coming in the fall…Indeed, he says, one of the big questions many capital equipment execs will bring to this year's Semicon West event on July 7 is, "When will the 16/14 nm investments begin?"
In the same vein, Ed Sperling continued in Established Nodes Getting New Attention: "Work is under way to improve energy efficiency and boost performance without relying on multi-patterning or finFETs. As the price of shrinking features increases below 28nm, there has been a corresponding push to create new designs at established nodes using everything from near-threshold computing to back biasing and mostly accurate analog sensors."
And a week later Samuel Wang, an analyst with Gartner, in Who’s Winning The FinFET Foundry Race? wrote: “Short-term, during the first two years of finFET production, there is no need for more than 50,000 wafers a month capacity from all foundries to satisfy the market demand for finFETs, …In the long run and before 2018, there is no need to have more than 250K wafers a month capacity to support the market demand for finFETs." The EDA industry also is recognizing this paradigm shift. Dr. Aart de Geus in his keynote to the 2014 Synopsys User Group titled Designing Change Into Semiconductor Techonomics, recognized this shift with a series of slides articulating how EDA tools that were developed to support the new technology nodes could also benefit design efforts of old nodes:
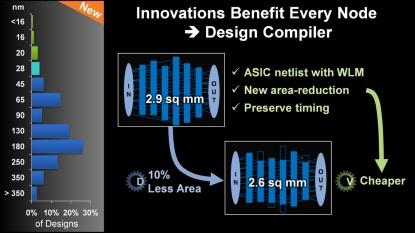
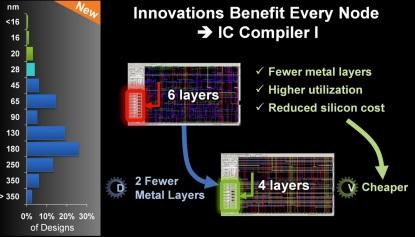
The IP industry is recognizing this paradigm shift as well, visible in IP Reaches Back To Established Nodes: "As SoC developers shift backward to established nodes, steps can be taken to improve the IP’s functionality. Driven by the IoT and wearable market opportunity, SoC developers are shifting backward to established nodes, and what is learned at the leading-edge nodes is being leveraged in reverse as IP is ported backward to improve functionality."
There also a clear effort to add value and innovation to older nodes by incorporating technology such as SOI and low Vt, known as sub-threshold designs. Most notable was the recent Samsung announcement of licensing FD-SOI from ST Micro for the established node of 28 nm. Some quotes from the articles above illustrate this trend:
* Krishna Balachandran, product marketing director for low power at Cadence. “Threshold voltage manipulation like forward biasing has been selectively used to speed up critical portions of the IP at the expense of increased leakage that is restricted to those sections of the IP without significant overall impact.”
* ARM Fellow Rob Aitken said energy savings are significant using the same exact processors differently. Moreover, it’s most effective at established process geometries where there are no finFETs. But it isn’t a simple process. (For a deeper understanding of this subject, click here). “We can get 4X to 6X improvements in energy,” said Aitken. “That doesn’t come for free, because we have to make some design changes to allow the design to operate down at this low energy point. But if we do this wrong, the overhead we have to add to get these savings is more than you get in terms of a benefit.”
* Mary Ann White, director of product marketing for the galaxy design platform at Synopsys: "Body biasing is another technique that is being recycled. It entered the picture at 90nm, when design teams found they could reduce leakage by as much as 30%. Even at 45/40nm, savings were in the 20% to 25% range. But at 28nm, the benefit for bulk CMOS dropped to as low as 2%,...When you use biasing, you are using extra tracks and extra resources, which may include one or two extra rails,” said White. “But the benefit was falling off at 28nm using planar CMOS. Interest is picking up again with FD-SOI. What’s interesting about this is we used to insert biasing at the back end, where you require a bulk n-well or p-well pin. But recently we’ve had a request to add that capability into UPF. We rolled that out with skepticism on our part, but we’ve been getting a lot of interest. If you’re adding 5% area for better power, it’s worth it.” (See related discussion.)
This paradigm shift could be a real blessing to the industry. The escalating costs drove out VCs from investing in semiconductor start-ups, drastically narrowed the number of vendors and the number of advanced new designs. It left little room for innovation or anything other than rushing to the next technology node. Now it seems that a whole new industry dynamic is taking place, innovation is being embraced, new markets are being explored, and hopefully we will see the return of VCs with the increase of semiconductor vendors and technologies.
This is also the time to pay increased attention to semiconductor technologies that could offer better intrinsic devices without traditional dimensional scaling. Most notable among those would be, SOI, Monolithic 3D, and Sub-threshold design. The 2014 S3S Conference scheduled for October 6-9, 2014, at the Westin San Francisco Airport would be a great opportunity to learn more about those technologies as it provides the latest research results along with workshops, tutorials and range of invited papers. The conference advance program is now available at < http://s3sconference.org/program/ >. It looks now to be the one conference that active members of the semiconductor industry should not miss.
There also a clear effort to add value and innovation to older nodes by incorporating technology such as SOI and low Vt, known as sub-threshold designs. Most notable was the recent Samsung announcement of licensing FD-SOI from ST Micro for the established node of 28 nm. Some quotes from the articles above illustrate this trend:
* Krishna Balachandran, product marketing director for low power at Cadence. “Threshold voltage manipulation like forward biasing has been selectively used to speed up critical portions of the IP at the expense of increased leakage that is restricted to those sections of the IP without significant overall impact.”
* ARM Fellow Rob Aitken said energy savings are significant using the same exact processors differently. Moreover, it’s most effective at established process geometries where there are no finFETs. But it isn’t a simple process. (For a deeper understanding of this subject, click here). “We can get 4X to 6X improvements in energy,” said Aitken. “That doesn’t come for free, because we have to make some design changes to allow the design to operate down at this low energy point. But if we do this wrong, the overhead we have to add to get these savings is more than you get in terms of a benefit.”
* Mary Ann White, director of product marketing for the galaxy design platform at Synopsys: "Body biasing is another technique that is being recycled. It entered the picture at 90nm, when design teams found they could reduce leakage by as much as 30%. Even at 45/40nm, savings were in the 20% to 25% range. But at 28nm, the benefit for bulk CMOS dropped to as low as 2%,...When you use biasing, you are using extra tracks and extra resources, which may include one or two extra rails,” said White. “But the benefit was falling off at 28nm using planar CMOS. Interest is picking up again with FD-SOI. What’s interesting about this is we used to insert biasing at the back end, where you require a bulk n-well or p-well pin. But recently we’ve had a request to add that capability into UPF. We rolled that out with skepticism on our part, but we’ve been getting a lot of interest. If you’re adding 5% area for better power, it’s worth it.” (See related discussion.)
This paradigm shift could be a real blessing to the industry. The escalating costs drove out VCs from investing in semiconductor start-ups, drastically narrowed the number of vendors and the number of advanced new designs. It left little room for innovation or anything other than rushing to the next technology node. Now it seems that a whole new industry dynamic is taking place, innovation is being embraced, new markets are being explored, and hopefully we will see the return of VCs with the increase of semiconductor vendors and technologies.
This is also the time to pay increased attention to semiconductor technologies that could offer better intrinsic devices without traditional dimensional scaling. Most notable among those would be, SOI, Monolithic 3D, and Sub-threshold design. The 2014 S3S Conference scheduled for October 6-9, 2014, at the Westin San Francisco Airport would be a great opportunity to learn more about those technologies as it provides the latest research results along with workshops, tutorials and range of invited papers. The conference advance program is now available at < http://s3sconference.org/program/ >. It looks now to be the one conference that active members of the semiconductor industry should not miss.




















 RSS Feed
RSS Feed