Bill Dally, Chief Scientist of nVIDIA and Professor at Stanford University, gave a great keynote speech on the future of computing recently. Let's discuss his presentation today...
A couple of years back, Bill Dally, the Chairman of Stanford University's Computer Science Department, did something really interesting. He took a break from academia to accept a full-time position as Chief Scientist and VP of Research at nVIDIA. When the New York Times asked him about his career move, he said, "It seemed to me that now is the time you want to be out there bringing products to the marketplace rather than writing papers. We are at the cusp of a computing revolution."
What does Bill Dally work on at nVIDIA? He leads a team of 25 engineers developing a radically new ExaScale Computing System called Echelon. In a keynote speech at the 2011 International Parallel & Distributed Processing Symposium, he described his vision for the future of computing and gave a preview of Echelon.
Why Future Computing Systems need to be Different
As you'd know, we have historically improved performance with a combination of device scaling and Instruction Level Parallelism (ILP). With leakage power emerging as a constraint in the mid 2000s, supply voltage could no longer be lowered, said Dally. Benefits of device scaling reduced. ILP benefits were "mined out" around the year 2000 too. New ideas are therefore needed for future computing systems. "To build an ExaScale machine in a power budget of 20MW requires a 200-fold improvement in energy per instruction: from 2nJ to 10pJ", noted Dally. "Only 4x is expected from improving technology as per the semiconductor roadmap. The remaining 50x must come from improvements in architecture and circuits." With this exciting preamble, Dally started talking ideas.
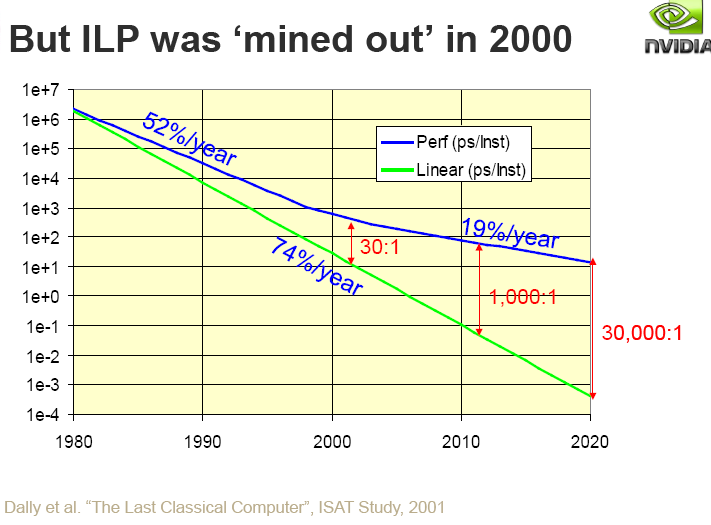
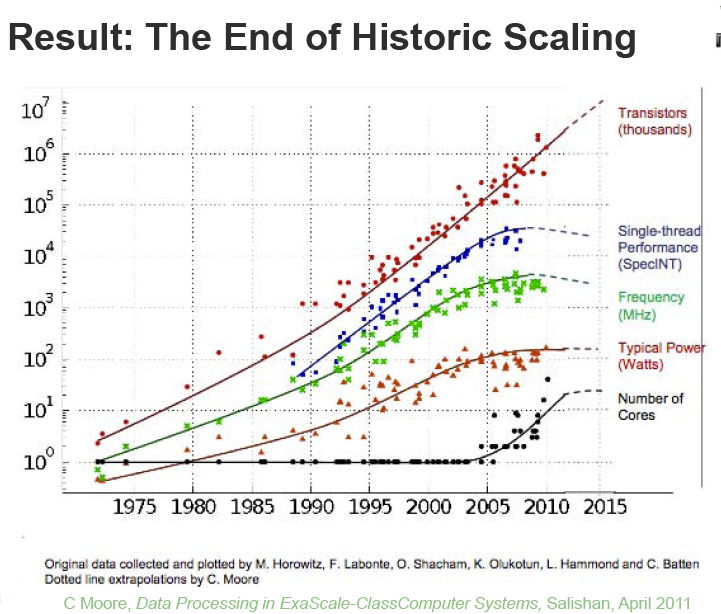
Figure 1: Conventional techniques to boost performance are no longer applicable
(Source: W. Dally, Keynote at IPDPS 2011).
(Source: W. Dally, Keynote at IPDPS 2011).
Tackling Power Issues due to Interconnects
Power is expected to be a major issue for ExaScale systems. One important source of power consumption is interconnect, according to Dally. He quoted data from nVIDIA's 28nm chips. See Figure 2. For a floating point operation, he said performing the computation costs 20pJ and for an integer operation, the corresponding number is 1pJ. However, getting the operands for this computation from local memory (situated 1mm away) consumes 26pJ. If the operands need to be obtained from the other end of the die, it requires 1nJ while if the operands need to be read from DRAM, the cost is 16nJ. The energy required for computation is significantly smaller than the energy needed for interconnects! This trend is expected to get worse with scaling, said Dally.
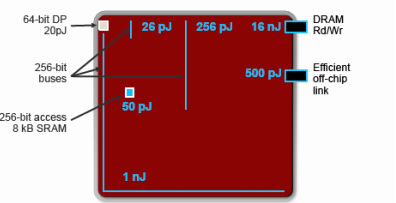
Figure 2: Computation cost is significantly lower than communication cost in 28nm nVIDIA chips (Source: W. Dally).
Dally suggested a multi-pronged strategy to address interconnect power consumption. At the application level, he feels programmers should try to minimize communication, even if it requires additional computation. For example, if the energy cost of moving data across the die is high, programs should recompute the data locally whenever possible. The compiler should be able to figure out when it is energetically favorable to recompute or to move data, and should also try to sub-divide problems to minimize communication cost. At the architectural level, Dally feels providing flexibility is key, and explained this with nVIDIA's Echelon architecture, depicted in Figure 3.
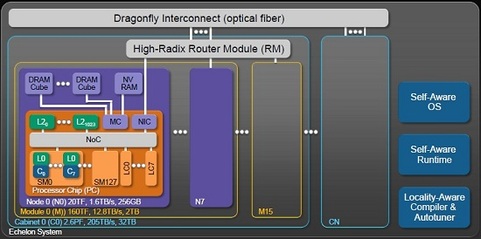
Figure 3: nVIDIA's Echelon Architecture
The Echelon architecture consists of multiple throughput optimized stream processors (called SM0... SM127) that are simple, in-order cores and a few latency optimized cores (LC0...LC7) that are optimized to maximize utilization of ILP with superscalar, out-of-order execution. The latency optimized cores burn 50x the energy per operation compared to throughput optimized cores for 3x the performance, and are utilized just for critical paths in the program. A network-on-chip architecture is utilized to manage interconnect resources efficiently. The most interesting part of Echelon, in my opinion, is the memory system that is completely configurable based on the needs of the application. Applications can have flat or hierarchical memory systems based on what is optimal for them. This unique memory system places data close to computation elements and minimizes the interconnect energy required to load operands from memory.
Tackling Power Issues due to Overhead
Dally presented the data in Figure 4 which depicts the overhead associated with branch prediction, register renaming, reorder buffers, scoreboards and other functionality common in today's superscalar, out-of-order cores. For a 20pJ operation, this overhead can be as high as 2000pJ! To tackle this, Echelon uses multiple strategies. Throughput optimized in-order cores are used whenever possible and latency optimized out-of-order cores are used only for critical paths. VLIW-type cores are used where the compiler does the scheduling. A multi-stage register hierarchy is utilized with a bulk of the data available on operand register files located close to computation units.
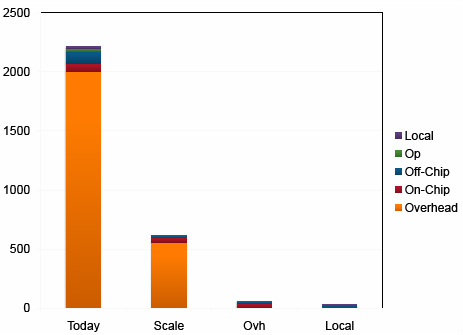
Figure 4: Overhead from superscalar, out-of-order execution (Source: W. Dally)
Programming
The biggest challenge with 1000 core chips such as Echelon will be programming them, said Dally. He recommended developing programming languages which describe parallelism and locality, but which are not specific to hardware implementations. Compilers and auto-tuners would then map programs to the specific hardware based on parallelism and locality considerations. "We are about to see a sea change in programming models," said Dally. "In high performance computing we went from vectorized Fortran to MPI and now we need a new programming model for the next decade or so," he said. "We think it should be an evolution of [Nvidia's] CUDA," said Dally. "But there are CUDA like approaches such as OpenCL, OpenMP and [Microsoft's] DirectCompute or a whole new language," he said.
If you'd like to see more details, please check out the video of Dally's presentation. You can find it at http://techtalks.tv/talks/54110 Before I sign off, let's talk about 3D integration's possible role in Dally's vision. While describing Figure 3, Dally talked about how nVIDIA wants to use 3D-based wide I/O DRAM for this application. This could allow low-energy and high-performance DRAM access. If you take a look at Figure 2, it will be clear that short wires enabled by monolithic 3D could reduce energy per operation significantly too.
- Post by Deepak Sekar








 RSS Feed
RSS Feed